雷達(dá)數(shù)字信號處理解決方案
1、背景
數(shù)字信號處理是現(xiàn)代通信、雷達(dá)和電子對抗設(shè)備的重要組成部分。在實際應(yīng)用中,利用數(shù)字信號處理技術(shù)對接收數(shù)據(jù)進(jìn)行處理,不僅可以實現(xiàn)高精準(zhǔn)的目標(biāo)定位和目標(biāo)跟蹤,還能夠?qū)⒛繕?biāo)識別、目標(biāo)成像、精確制導(dǎo)、電子對抗等功能進(jìn)行拓展,實現(xiàn)多種業(yè)務(wù)的一體化集成。
在現(xiàn)代雷達(dá)系統(tǒng)中,隨著有源相控陣和數(shù)字波束形成(DBF)技術(shù)的廣泛應(yīng)用,接收前端存在大量的數(shù)據(jù)需要并行處理,并需要保證高性能和低延遲的特點。雷達(dá)日益復(fù)雜的應(yīng)用環(huán)境,讓雷達(dá)系統(tǒng)具備自適應(yīng)于探測目標(biāo)和環(huán)境的能力,數(shù)字信號處理部分也需要使用多種更加復(fù)雜的算法,并且可以做到算法模塊化,以及通過軟件配置功能模塊的參數(shù),實現(xiàn)軟件定義的功能。更大的數(shù)據(jù)處理帶寬能夠使雷達(dá)獲得更高的分辨率,更高的工作頻率使得雷達(dá)可以小型化,能夠在更小的平臺上安裝,這樣對于硬件平臺實現(xiàn)也有低功耗的要求。
在電子對抗設(shè)備中,可以在最短的時間內(nèi)對多個威脅目標(biāo)進(jìn)行快速分析和響應(yīng),同樣需要數(shù)字信號處理的相關(guān)算法具備高實時,高動態(tài)范圍和自適應(yīng)的特點。如何在寬頻噪聲的環(huán)境中尋找到目標(biāo)的特征數(shù)據(jù),如何在寬帶范圍內(nèi)制造虛假目標(biāo)實現(xiàn)全覆蓋,數(shù)字信號的處理性能是至關(guān)重要的設(shè)計因素。
加速云的SC-OPS和SC-VPX產(chǎn)品,針對5G通信和雷達(dá)的數(shù)字信號處理的要求,結(jié)合Intel最新14nm工藝的Stratix10 FPGA系列,提供了一套完整的硬件和軟件相結(jié)合的解決方案。SC-OPS產(chǎn)品作為單獨的硬件加速卡,通過PCIe插卡的方式實現(xiàn)與主機(jī)的通信功能,還可以通過多卡級聯(lián)的方式實現(xiàn)數(shù)字信號的分布式處理方案。SC-VPX產(chǎn)品是由FPGA業(yè)務(wù)單板、主控板和機(jī)箱組成的VPX系統(tǒng)。借助于FPGA可編程的特性,加速云提供了高性能數(shù)學(xué)加速庫FBLAS和FFT的RTL級IP,具有高性能和算法參數(shù)可配置的特點實現(xiàn)了多重信號分類(MUSIC)和自適應(yīng)數(shù)字波束形成(ADBF)的核心算法,提高了5G通信和雷達(dá)在對抗干擾方面的性能。為了方便客戶使用高層語言開發(fā),加速云提供基于FPGA完整的OpenCL異構(gòu)開發(fā)環(huán)境,快速實現(xiàn)用戶自定義的信號處理加速方案。


圖1、加速云SC-OPS和SC-VPX產(chǎn)品
2、方案組成
2.1 基于SC-OPS產(chǎn)品的系統(tǒng)架構(gòu)圖
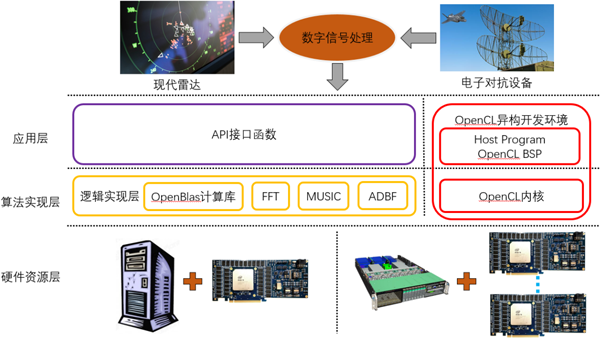
圖2、SC-OPS產(chǎn)品系統(tǒng)框圖
基于SC-OPS產(chǎn)品的系統(tǒng)分別由硬件資源層,算法實現(xiàn)層和應(yīng)用層三部分組成。
SC-OPS加速卡作為主要的硬件平臺,采用IntelStratix10 GX2800 FPGA器件,集成2753KLE資源和9.2TFLOPS單精度浮點計算能力。單板支持2個40/100G光口或電口,支持板間通信以及設(shè)備間級聯(lián)。板卡支持8個DDR4-2400MHz 72bits位寬的內(nèi)存通道(ES支持2133MHz),以及PCIeGen3 16Lane的主處理器通信接口。
通過在主機(jī)內(nèi)插入一張或多張SC-OPS加速卡的形式,可以實現(xiàn)不同性能的硬件集成。以一機(jī)八卡服務(wù)器為例,整機(jī)具備73.6TFLOPS的單精度浮點計算能力,并具有納秒級低延時特性,可應(yīng)用于高性能的數(shù)字信號處理的解決方案。加速云在算法實現(xiàn)層提供了基于FPGA邏輯實現(xiàn)的高性能數(shù)學(xué)加速庫FBLAS,F(xiàn)FT,MUSIC和ADBF核心算法,以上功能模塊都是以IP形式提供,并提供相應(yīng)的API接口函數(shù),通過PCIe接口實現(xiàn)在應(yīng)用層的調(diào)用,從而可以搭建軟件定義雷達(dá)系統(tǒng),實現(xiàn)超高性能高靈活的雷達(dá)仿真平臺。對于更加關(guān)注于自定義算法實現(xiàn)的用戶來說,加速云還可以支持面向OpenCL的FPGA異構(gòu)平臺開發(fā)環(huán)境,提供了SC-OPS板卡對應(yīng)的BSP,用戶只需要自行編寫OpenCL Kernel和Host程序,即可以快速的實現(xiàn)相關(guān)算法的二次開發(fā)。
2.2 基于SC-VPX產(chǎn)品的系統(tǒng)架構(gòu)圖
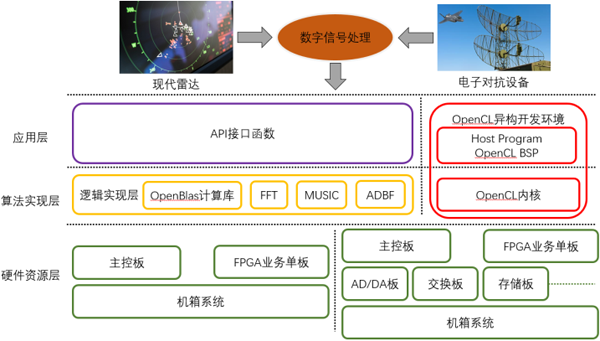
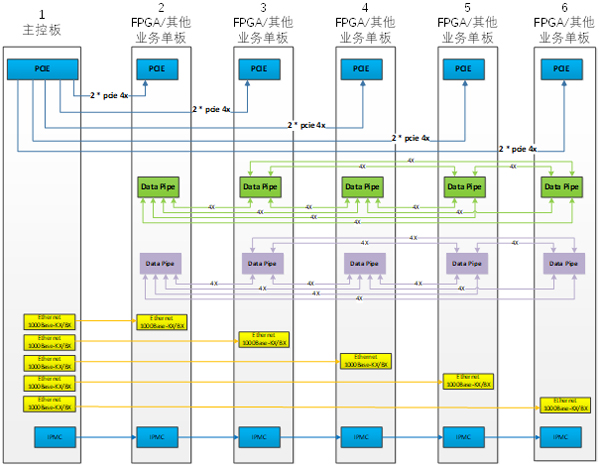
圖3、SC-VPX產(chǎn)品系統(tǒng)框圖
基于SC-VPX產(chǎn)品的系統(tǒng),與SC-OPS相比,區(qū)別在于硬件平臺實現(xiàn)。SC-VPX系統(tǒng)由5塊FPGA業(yè)務(wù)單板,1塊X86主控板和6U標(biāo)準(zhǔn)VPX機(jī)箱組成。其中FPGA業(yè)務(wù)單板采用板載XEON-DX86主控和1~2片Stratix10 GX2800 FPGA器件的方案,集成2753K*2 LE資源和9.2 *2 TFLOPS單精度浮點計算能力。每片F(xiàn)PGA支持4個DDR4-2400MHz 72bits位寬的內(nèi)存通道。前面板支持8個17.5Gbps光口,背板提供32個10.3125Gbps的高速接口,支持業(yè)務(wù)單板之間的全mesh高速互聯(lián)網(wǎng)絡(luò),X86主控板與業(yè)務(wù)單板之間采用PCIe和GE的雙控通信方案。
用戶可以選擇加速云提供的主控板和多塊FPGA業(yè)務(wù)單板,整機(jī)最高可以支持92TFLOPS單精度浮點處理能力,配合相關(guān)算法IP,實現(xiàn)多種數(shù)字信號處理的算法或者分布式實現(xiàn)大容量數(shù)據(jù)處理的算法。由于SC-VPX整套系統(tǒng)都是符合OpenVPX的標(biāo)準(zhǔn),用戶可以添加其他各種功能板卡,包括AD/DA板、RapidIO交換板、存儲板等,結(jié)合加速云的主控板和FPGA業(yè)務(wù)單板,組建成一套完整的信號接收處理雷達(dá)系統(tǒng),無論是應(yīng)用于相關(guān)產(chǎn)品還是科研,都可以幫助用戶實現(xiàn)系統(tǒng)級的解決方案。
3、系統(tǒng)優(yōu)勢
3.1優(yōu)異的能效比
能效比是評估數(shù)字信號處理時一個關(guān)鍵的指標(biāo),即GFLOPS per Watt。表1中羅列了各類設(shè)備平臺的數(shù)字信號處理能力的能效比,加速云采用IntelStratix10 FPGA的方案具備最優(yōu)的能效比。
| 類型 | 系列 | 單精度浮點 運算能力 |
功耗 | 能效比 |
| FPGA | IntelStratix10 | 9.2TFLOPS | 120W | 76.6 GFLOPS/W |
| FPGA | IntelArria10 | 1.5TFLOPS | 30W | 50 GFLOPS/W |
| DSP | TITMS320C6678 | 160GFLOPS | 15W | 10.6 GFLOPS/W |
| GPU | NVIDIA Tesla P40 | 12T FLOPS | 250W | 48 GFLOPS/W |
| CPU | 至強(qiáng)12核(IntelXEONE5-2697) | 219GFLOPS | 130W | 1.68 GFLOPS/W |
表1、各平臺數(shù)字信號處理能力效能比的對比
3.2 FPGA IO靈活可編程
FPGA最大的特點在于IO可編程,可以提供各種高速和低速IO的協(xié)議標(biāo)準(zhǔn),匹配用戶實現(xiàn)多樣系統(tǒng)互聯(lián)的要求。比如SC-OPS板卡的2個高速互聯(lián)接口,分別可以配置為40GE,100GE或SRIO的標(biāo)準(zhǔn)。SC-VPX FPGA業(yè)務(wù)單板的背板提供32個10.3125Gbps的高速接口支持與背板間的全mesh網(wǎng)絡(luò)接口,分別可以配置為10GE,40GE或SRIO的標(biāo)準(zhǔn)。
3.3高性能的算法IP
加速云基于FPGA平臺上提供了數(shù)字信號處理相關(guān)算法的IP,IP的性能決定了數(shù)字信號處理系統(tǒng)的性能,包括動態(tài)范圍,信號損耗,信噪比,延時等因素。
以信號處理中常用的FFT傅里葉變換為例,相比最新的DSP平臺,加速云提供的RTL級IP,使用FPGA符合IEEE 754標(biāo)準(zhǔn)的單精度浮點數(shù)字信號處理(DSP)單元,可以實現(xiàn)更低的計算時間。
| FFTSize | PerformanceofComputingFFT (time, ms) using TMS320C6678 | |||
| 1 core | 2 cores | 4 cores | 8 cores | |
| 16K | 0.473 | 0.261 | 0.159 | 0.131 |
| FFT Size | Performance of Computing FFT (time, ms) using FPGA | |||
| 1 PE | 2 PEs | 4 PEs | 8 PEs | |
| 16K | 0.16 | 0.04 | 0.01 | 0.003 |
表2、DSP和FPGA平臺實現(xiàn)FFT算法的計算時間對比
以下是加速云提供的基于FPGA實現(xiàn)高性能數(shù)學(xué)加速庫FBLAS的相關(guān)性能。可以看出,借助FPGA天然的并行處理的優(yōu)勢,加速云提供的算法IP,可以幫助用戶實現(xiàn)數(shù)字信號處理系統(tǒng)的快速優(yōu)化,極大縮短了用戶產(chǎn)品Time-to-Market的時間。
| 算法名稱 | 參數(shù) | 數(shù)據(jù)格式 | 處理性能 |
| 矩陣求逆 | 144*144維復(fù)數(shù) | FP32 | 120us |
| 矩陣求逆 | 72*72維復(fù)數(shù) | FP32 | 53.6us |
| 矩陣求逆 | 24*24維復(fù)數(shù) | FP32 | 10.32us |
| 矩陣求逆 | 12*12維復(fù)數(shù) | FP32 | 3.76us |
| 矩陣QR分解 | 64*64維復(fù)數(shù) | FP32 | 46.41us |
| 矩陣QR分解 | 16*16維復(fù)數(shù) | FP32 | 4.99us |
| 矩陣QR分解 | 8*8維復(fù)數(shù) | FP32 | 2.5us |
| 特征值分解(基于QR分解,16次迭代) | 64*64維復(fù)數(shù) | FP32 | 5200us |
| 特征值分解(基于QR分解,16次迭代) | 16*16維復(fù)數(shù) | FP32 | 150us |
| 特征值分解(基于QR分解,16次迭代) | 8*8維復(fù)數(shù) | FP32 | 65us |
| 協(xié)方差矩陣(快拍數(shù)K=256,通道數(shù)N=8) | 8維復(fù)向量 | FP32 | 30us |
| 協(xié)方差矩陣(快拍數(shù)K=256,通道數(shù)N=16) | 16維復(fù)向量 | FP32 | 60us |
| 協(xié)方差矩陣(快拍數(shù)K=256,通道數(shù)N=64) | 64維復(fù)向量 | FP32 | 128us |
| 線性方程求解 | 200維 | FP64 | 420us |
表3、FPGA實現(xiàn)高性能數(shù)學(xué)加速庫FBLAS性能示例
3.4完整的OpenCL異構(gòu)開發(fā)環(huán)境
加速云SC-OPS和SC-VPX產(chǎn)品都可以支持面向OpenCL的FPGA異構(gòu)平臺開發(fā)環(huán)境,提供全面的數(shù)學(xué)庫支持,解決了傳統(tǒng)FPGA遇到的時序收斂、DDR存儲器管理以及PCIe主處理器接口等難題。另外加速云也支持將高性能算法IP作為定制化組件,與OpenCLKernel集成在一起,提供靈活的算法配置解決方案。
4、應(yīng)用案例
4.1多重信號分類(MUSIC)
MUSIC算法是經(jīng)典的空間譜估計算法,實現(xiàn)波達(dá)方向估計(DOA)的相關(guān)應(yīng)用。在電子偵察和電子對抗等對實時性要求嚴(yán)格的領(lǐng)域中,如何選用合適的平臺實現(xiàn)并滿足系統(tǒng)的響應(yīng)處理速度,成為了設(shè)計者頗為頭疼的問題。整個MUSIC算法計算復(fù)雜度和靈活度都很大,而且電子對抗系統(tǒng)都有浮點處理的要求,所以大多用戶會采用DSP處理器的方案,處理時間停留在ms量級。加速云采用Intel集成全新浮點計算單元的FPGA,全硬件實現(xiàn)了基于MUSIC算法的空間譜估計DOA全部算法(MUSIC算法是基于加速云高性能數(shù)學(xué)加速庫FBLAS搭建的,所有組成IP都可以單獨調(diào)用)。相比DSP處理器,極大提升了MUSIC算法的實時性,超過10倍以上的性能改進(jìn)。
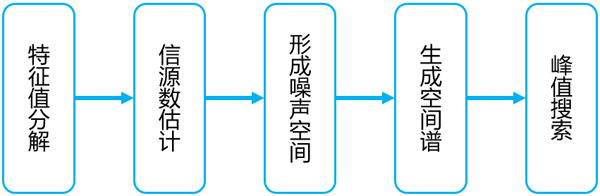
圖4、FPGA實現(xiàn)MUSIC算法的處理流程
MUSIC算法實現(xiàn)的相關(guān)性能如下:
· 特征值和特征向量的數(shù)值相對Matlab中EIG函數(shù)計算結(jié)果的偏差均小于10-5· 算法實現(xiàn)以單精度浮點為主,結(jié)合部分雙精度浮點
· 全部處理時間<120us(TI6678的處理時間是ms級)
4.2自適應(yīng)數(shù)字波束形成(ADBF)
隨著有源相控陣?yán)走_(dá)的廣泛應(yīng)用,如何有效增強(qiáng)期望信號和抑制無用信號,也是設(shè)計者需要考慮的問題。ADBF技術(shù)利用天線陣元的采樣數(shù)據(jù),自適應(yīng)更新信號的權(quán)值,使陣列天線形成特定的期望形狀。由于天線陣元通道數(shù)量大,需要實現(xiàn)海量數(shù)據(jù)的計算,相關(guān)平臺實現(xiàn)必須具有高集成度、高數(shù)據(jù)吞吐率和高數(shù)據(jù)并行計算的特點。
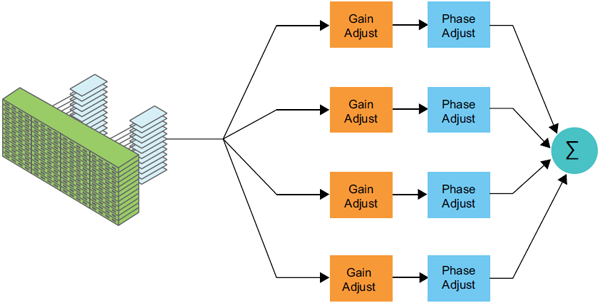
圖5、DBF原理示意圖
加速云借助高性能數(shù)學(xué)加速庫FBLAS,通過高維數(shù)的矩陣求逆的算法,完全在FPGA內(nèi)實現(xiàn)了ADBF的算法。
ADBF算法實現(xiàn)的相關(guān)性能如下:

方位維天線方向圖 俯仰維天線方向圖
| 算法名稱 | 數(shù)據(jù)格式 | 性能指標(biāo)(單拍) | 性能指標(biāo)(連續(xù)) | 功耗 |
| 方位維運算 | FP32 | 455us | 245us | 30W |
| 俯仰維運算 | FP32 | 335us | 148us | 30W |
5、結(jié)論
通過參與了國內(nèi)眾多實際雷達(dá)數(shù)字信號處理相關(guān)產(chǎn)品或是科研的研發(fā)和技術(shù)合作,加速云累計了大量的經(jīng)驗,在此基礎(chǔ)上推出的SC-OPS和SC-VPX產(chǎn)品及高性能數(shù)學(xué)加速庫FBLAS、多重信號分類(MUSIC)、自適應(yīng)數(shù)字波束形成(ADBF)等IP庫,可以幫助用戶實現(xiàn)系統(tǒng)級的解決方案。通過持續(xù)推出高密度高性能硬件平臺,高性能RTL級加速IP,配合高性能分布式軟件搭建高性能、低延時靈活配置的軟件定義平臺,推動了雷達(dá)和電子對抗設(shè)備向更先進(jìn)設(shè)備的演變。
 粵公網(wǎng)安備 44030902003195號
粵公網(wǎng)安備 44030902003195號